
Source: Dev Community
Are you preparing for coding interviews and aiming to land your dream job in the tech industry? Having a solid grasp of data structures and algorithms is vital for acing those interviews, as they are the key components of any coding challenge.
This article is designed to guide you through the must-know data structures and algorithms, providing examples, interesting facts, and valuable resources to help you crack those interviews with confidence.
Let's dive in!
Introduction: (What are Data Structures? What are its types?)
Data structures and algorithms are the backbone of computer science, essential for building efficient software. In this blog post, we'll delve into the must-know data structures and algorithms, providing examples and interesting facts to keep you engaged. We'll also share some useful resources to further your understanding. There are many Data Structures and Algorithms, in this article we will cover 10 must-know ones.
Data structures can be broadly categorised into two types: linear and non-linear. Here's a brief overview of each category and some common data structures belonging to them:
Linear Data Structures:
In linear data structures, elements are arranged sequentially, and each element is connected to its previous and next elements in a linear order.
Common linear data structures include:
Arrays: A fixed-size, indexed collection of elements of the same data type.
Linked Lists: A collection of nodes, where each node contains an element and a reference to the next node in the sequence. There are different types of linked lists, such as singly linked lists, doubly linked lists, and circular linked lists.
Stacks: A collection of elements with a Last-In-First-Out (LIFO) order. Elements can be added (pushed) and removed (popped) from the top of the stack.
Queues: A collection of elements with a First-In-First-Out (FIFO) order. Elements are added (enqueued) to the rear and removed (dequeued) from the front. Variations include priority queues, double-ended queues (deque), and circular queues.
Non-linear Data Structures:
In non-linear data structures, elements are organised in a hierarchical or interconnected manner, allowing for more complex relationships between elements.
Common non-linear data structures include:
Trees: A collection of nodes connected by edges, with no cycles, and organised hierarchically. There are various types of trees, such as binary trees, binary search trees, AVL trees, and B-trees.
Graphs: A collection of nodes (vertices) connected by edges, representing relationships between objects. Graphs can be directed (edges have a direction) or undirected, and may have weighted or unweighted edges. Examples include social networks, transportation systems, and computer networks.
Hash Tables (HashMaps): A key-value store that allows for constant-time storage and retrieval of data using a hashing function. Hash tables can be implemented using arrays, linked lists, or other data structures.
Tries (prefix trees): A tree-like data structure used to store a dynamic set or associative array, where the keys are usually strings. Tries are particularly efficient for searching and auto-completion tasks.
Understanding and selecting the appropriate data structure is crucial for building efficient and scalable software applications.
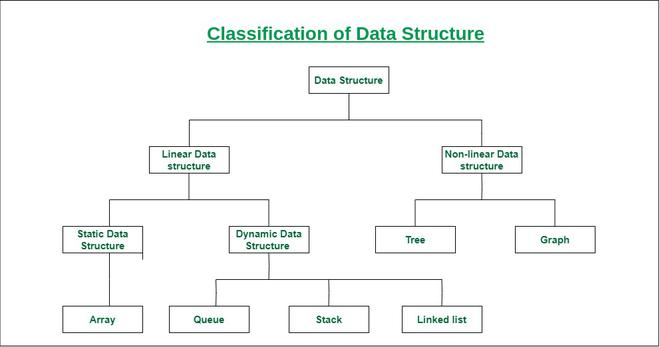
A Quick Summary (Source: GeeksForGeeks)
YES, its possible !!
Thanks to USFCA and Prof David Galles,
Data Structure Visualization (usfca.edu) - here’s the resource, have fun!
Let's look at them one by one:
Array
An array is a fixed-size, indexed collection of elements of the same data type, providing constant-time access to elements via their index. Arrays store data in a continuous manner and have a fixed size. To use an array, declare the data type, size, and values. Elements can be accessed using their index, which starts at 0. Arrays can be used to store and manipulate data efficiently, but resizing is difficult and costly.

Real Life Example: In the software industry, arrays are commonly used in image processing. Pixels in an image are represented as a two-dimensional array, where each cell contains color information. This allows for easy manipulation of images, such as applying filters or resizing.
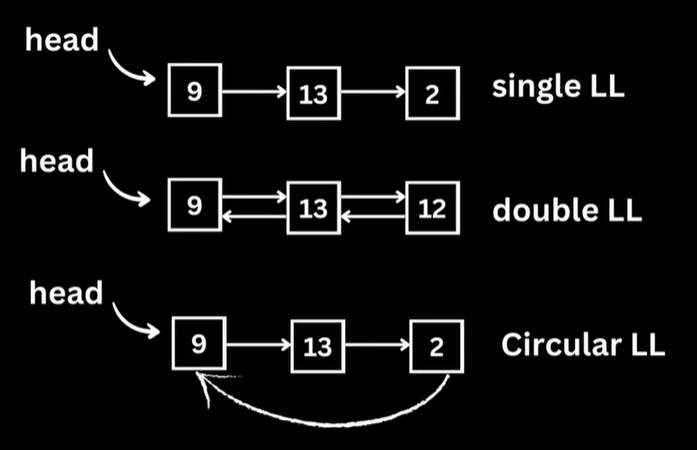
Linked List

This is what a LinkedList looks !
A linked list is a linear data structure comprising nodes, each containing an element and a reference to the next node. They offer dynamic sizing and constant-time insertion and deletion but require linear time to access elements. In Linked Lists, data can be accessed sequentially.
Note. Arrays have fixed size, LinkedLists can expand/shrink in size.
Types of LinkedLists:
Real life example: Spotify playlist. Music players often use linked lists to maintain playlists. Each node represents a song, and the 'next' pointer connects to the subsequent song in the playlist. Linked lists allow for efficient insertion and deletion of songs without the need for resizing, unlike arrays.
Recommended Article: "The Art of Computer Programming" by Donald E. Knuth, specifically Chapter 2.2.3.( Accessible here)
Stacks and Queues
Stacks and queues are two popular linear data structures that organize data in a specific order. Stacks follow the LIFO principle, where the last item added is the first item removed, making them ideal for handling function calls and implementing recursive algorithms. On the other hand, queues follow the FIFO principle, where the first item added is the first item removed, making them suitable for managing resources in operating systems and scheduling tasks. In a stack, elements are added and removed from one end, while in a queue, they are added to one end and removed from the other. Both stacks and queues enable efficient constant-time operations and have various practical applications in computer science.
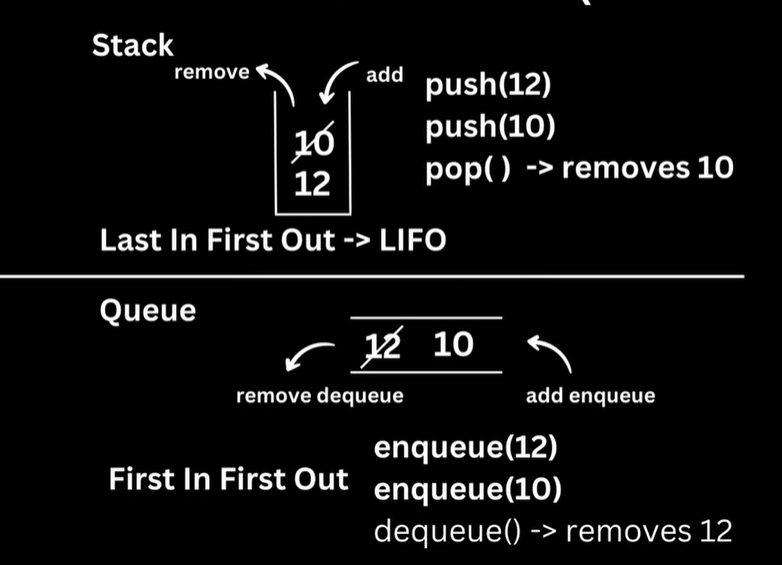
Real life example: Web browsers use stacks to manage the back and forward buttons. When a user navigates to a new page, the current page is pushed onto a stack. Clicking the back button pops the top page from the stack, while the forward button uses a separate stack to track the forward navigation.
Recommended Blog: Vaidehi Joshi’s blogs on Stacks and Queues
HashMap
It's a fancy term for a cool way to quickly find stuff in a computer program.
Imagine you have a huge box full of toys and you want to find a specific toy quickly. If the toys are sorted alphabetically, you can find it faster. Hashing is like sorting the toys, but even faster!
Think of hashing like a treasure map that shows you exactly where to find the treasure. The map is like a code that helps you find things quickly and easily. In programming, Hashing is used to quickly find data in a collection, like a HashMap or HashSet. These collections work like magic boxes that can find things super-fast, without having to search every single item one-by-one.
HashMaps use keys to help find specific values, while HashSets store a group of unique values.
HashMap, also known as hash table or dictionary, is a data structure that allows constant-time storage and retrieval of key-value pairs using a hashing function. However, performance may degrade with a poorly designed hashing function or high load factors.

Real Life Example: In a content management system (CMS), HashMaps can be used to store and retrieve user preferences. The key represents the user ID, and the value contains the user's preferences. This allows for quick access and updating of individual user preferences.
Recommended Article: "Hash Table" by Thomas H. Cormen et al. in the MIT Encyclopedia of the Cognitive Sciences. (Accessible here)
Trees
Trees are hierarchical data structures that consist of nodes connected by edges, with no cycles.
They are used to represent hierarchical relationships, such as file systems or organizational structures. Trees have various applications in computer science, including networking and database management systems. Binary trees are a specific type of tree where every node can have at most two children, making them ideal for efficient searching and sorting operations. The binary tree's balanced form, called the AVL tree, is widely used in database indexing, and the B-tree variant is used in file systems and databases.
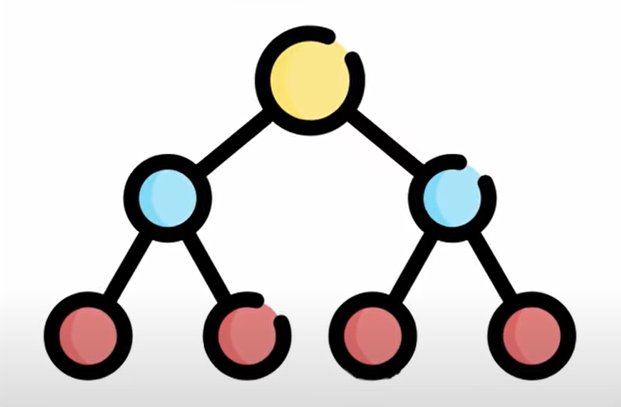
Be sure to learn how to iterate through trees using BFS and DFS and also revise the Binary search tree concept here. (Link: https://youtu.be/bvGEZpdPtpA)
Sorting Algorithms
Sorting algorithms arrange data in a specific order and include Bubble Sort, Selection Sort, Insertion Sort, Merge Sort, Quick Sort, and Heap Sort. Merge Sort is a divide-and-conquer algorithm that sorts non-primitive data structures, while Quick Sort sorts large datasets without requiring extra space. Sorting algorithms are essential in computer science for efficient searching and retrieval of data.

Merge Sort is Stable but uses additional Space!
Real Life Example: E-commerce websites use sorting algorithms to display products based on different criteria, such as price, customer ratings, or date added. A suitable sorting algorithm, like Merge Sort or Quick Sort, can help ensure that products are displayed in the desired order quickly and efficiently.
Searching Algorithms
Searching algorithms find the position of a specific element in a data structure. Common searching algorithms include Linear Search, Binary Search, and Interpolation Search.
Binary Search (most efficient searching algorithm).BFS and DFS - Breadth First Search and Depth First Search are popular searching algorithms which use Queue and Stack Data Structure. They are mostly used in Tree Data structure , but can also be used to search in a tabular data!

Real Life Example: Search engines use searching algorithms, like Binary Search, to locate specific keywords within a sorted index. This enables the search engine to quickly display relevant results to a user's query.
Recursion
Recursion is a problem-solving technique that solves problems by breaking them into smaller, similar problems until a base case is reached. Recursive algorithms can lead to elegant and concise solutions but may cause high memory usage due to the call stack.
Its a technique by which we can solve a lot of coding questions. Recursion refers to calling the function from within the function body itself. It stops when it meets a certain criteria, referred to as ‘Base Condition’

Here’s what recursion looks like (Source: Google)
Real Life Example: In computer graphics, recursion is used to create complex patterns and images through a technique called fractals. The Mandelbrot set, for instance, is generated using a recursive algorithm, resulting in intricate and visually stunning patterns.
Memoization
Memoization is an optimization technique used to speed up recursive algorithms by storing the results of expensive function calls and returning the cached result when the same inputs occur again. The best use case is of Dynamic programming.
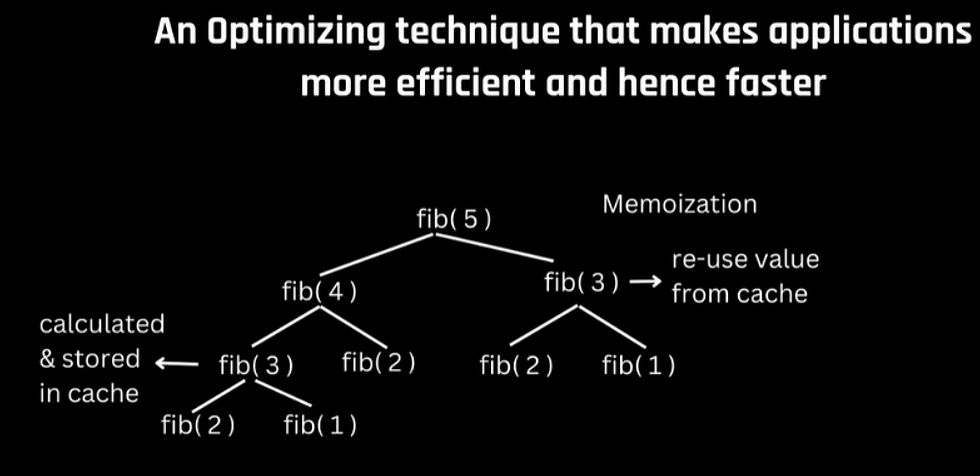
Calculating intermediate solutions again and again can cause wasteful utilisation of computer resources, something we don’t want. So,we build a cache.
Real Life Example: In natural language processing, memoization can be used to speed up algorithms that perform part-of-speech tagging. By caching the results of previous computations, memoization can help avoid redundant calculations and improve the overall performance of the tagging process.
Recommended Blog: (Accessible here)
Graphs
Graphs are a powerful data structure consisting of nodes (vertices) and edges, representing relationships between objects. They can be used to model a wide range of problems, such as social networks, transportation systems, and computer networks.
Real Life Example: Social networking platforms, like Facebook and LinkedIn, use graph data structures to represent connections between users. Graph algorithms can then be applied to analyze the relationships, such as finding the shortest path between two users or identifying communities within the network.
Recommended Book: "Graph Theory and Complex Networks: An Introduction" by Maarten van Steen.
Time and Space Complexity
Space complexity and time complexity are metrics used to analyze the efficiency of an algorithm or data structure:
Time Complexity: Represents the amount of time an algorithm takes to execute as a function of input size. It helps to compare the performance of different algorithms, considering how their execution time grows with increasing input size. Lower time complexity indicates better efficiency.
Space Complexity: Represents the amount of memory an algorithm consumes as a function of input size. It helps to evaluate the memory requirements of an algorithm or data structure, considering how memory usage grows with increasing input size. Lower space complexity indicates better memory efficiency.
For detailed explanation, refer this blog
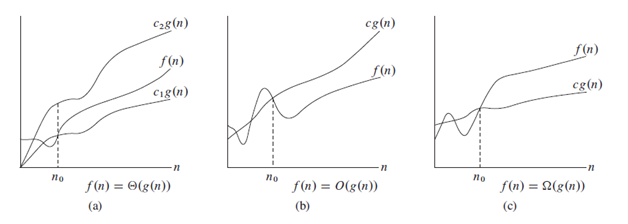
If you are interested in a detailed explanation on above mentioned concepts, checkout our video!! You will find code to common data structures and algorithms in JAVA on our GitHub!
We hope this article has provided you with a comprehensive understanding of the essential data structures and algorithms you need to know for coding interviews.
Remember, practice makes perfect!
Keep working on these concepts and apply them to real-world problems to sharpen your skills.
If you found this article helpful, please like and share it with your friends who are also preparing for coding interviews or looking to strengthen their computer science knowledge.
Good luck with your coding journey, and may you land that dream job!!
Comments